Librairie standard
Directory
Sources
Slide du cours C++ He-arc: 1240.2.09 Bibliothèque Standard cppref
1. Flux
- Un flux est une séquence d’octets transférée entre la mémoire et les périphériques.
- C’est le programme qui donne une signification aux octets d’un flux.
- Les flux fournissent une méthode unifiée de traiter les E/S quel que soient les périphériques et les types de données à échanger.
- Hiérarchie basée sur ios(in/out… a compléter)
Classes implémentant des flux:
iostream$ \Rightarrow $ E/S standard (clavier/écran)fstream$ \Rightarrow $ E/S dans les fichierssstream$ \Rightarrow $ E/S dans la mémoire (string)
Toutes ces classes redéfinissent les opérateurs<<et>>
2. Fichiers
Deux types de fichiers:
- texte (par défaut)
- binaire
Deux modes d’accès:
- séquentiel
- direct (random acces)
#include <fstream>
Trois classes:
ifstream$ \Rightarrow $ lectureofstream$ \Rightarrow $ ecriturefstream$ \Rightarrow $ les deux
Ouverture
Deux choix:
- constructeur
ifstream(char* nom, int mode)
ofstream(char* nom, int mode)
- méthode
open()open(char* nom, int mode)
Même signature, seules les valeurs par défaut changent.
Paramètres d’ouverture
Le paramètre mode est un champ de bits. On le combine avec l’opérateur bit à bit |.
ios::binary$ \Rightarrow $ Mode binaire (mode texte par défaut)ios::in$ \Rightarrow $ Lecture (défaut pourifstream)ios::out$ \Rightarrow $ Ecriture (défaut pourofstream)ios::app$ \Rightarrow $ Ajout à la fin (append)ios::trunc$ \Rightarrow $ Écrase le contenu précédent (truncate)ios::ate$ \Rightarrow $ position à la fin dés l’ouverture
exemple
Ouverture d’un fichier texte en écriture par ajout (append)
fstream("Log.txt", ios::out | ios::app)
Fermeture
close()
Exemples
#include<iostream>
#include<string>
#include<fstream>
using namespace std;
int main() {
ofstream fOut("monfichier.txt");
fOut << "PI= 3" << 3.14159 << '.' << endl;
fOut.close();
ifstream fIn("monfichier.txt");
string s; double n; char c;
fIn >> s >> n >> c;
fIn.close();
cout << s << "--" << n << "--" << c << endl;
return 0;
}
- L’utilisation des flux pour accéder aux fichiers soulève les mêmes problèmes que pour la console. Les caractères blancs sont concidérés comme des séparateurs. On peut utiliser la fonction
getline()pour les lire en entier. - La méthode utilisée est la même, seuls les périphériques changent.
Ecriture
#include <iostream>
#include <fstream>
using namespace std;
int main(){
int a = 1;
int t1[6];
double b = 9.87;
char c = 'W';
for (int i = 0; i < 6; ++i) {
t1[i] = 1000+i;
}
// ofstream f("toto.txt", ios::out | ios::binary);
ofstream f("poule.xyz");
if (!f.is_open()) {
cout << "Impossible d'ouvrir le fichier en ecriture\n";
return -1;
}
// ecrire dans le fichier binaire avec write
f.write((char *)&a, sizeof(int));
f.write((char *)&b, sizeof(double));
f.write((char *)&c, sizeof(char));
for (int i = 0; i < 6; ++i) {
f.write ((char *)&t1[i], sizeof(int));
}
// get size of file
f.seekp(0, ios::end); // aller à la fin
int size = f.tellp(); // obtenir la position et la retourner
cout << "la taille du fichier est: " << size << endl;
f.close();
cout << "Termine\n";
return 0;
}
output:
la taille du fichier est: 38
Termine
Ecriture avec «
int main() {
int a = 78;
int t1[6];
double b = 9.87;
char c = 'W';
for (int i = 0; i < 6; ++i) {
t1[i] = 1000+i;
}
// ofstream f("poule.xyz", ios::out | ios::binary);
ofstream f("poule.xyz");
if (!f.is_open()) {
cout << "Impossible d'ouvrir le fichier en ecriture\n";
return -1;
}
f << a << endl; // .write((char *)&a, sizeof(int));
f << a << endl; // .write((char *)&b, sizeof(double));
f << a << endl; // .write((char *)&c, sizeof(char));
for (int i = 0; i < 6; ++i) {
f << t1[i] << endl; // .write ((char *)&t1[i], sizeof(int));
}
return 0;
}
Lecture
#include<iostream>
#include<fstream>
using namespace std;
int main() {
int a;
double b;
int t1[6];
char c;
string s;
// ifstream f("poule.xyz", ios::in | ios::binary);
ifstream f("poule.xyz");
if (!f.is_open()) {
cout << "Impossible d'ouvrir le fichier en lecture\n";
return -1;
}
// lecture avec read
f.read ((char *)&a, sizeof(int));
f.read ((char *)&b, sizeof(double));
f.read ((char *)&c, sizeof(char));
for (int i = 0; i < 6; ++i)
{
f.read((char *)&t1[i], sizeof(int));
}
// get size of file
f.seekg(0, ios::end); // aller à la fin
int size = f.tellg(); // obtenir la pos et la retourner
cout << "La taille du fichier est: " << size << endl;
f.close();
cout << "a = " << a << endl;
cout << "b = " << a << endl;
cout << "c = " << a << endl;
for (int i = 0; i < 6; ++i)
{
cout << t1[i] << endl;
}
return 0;
}
output:
La taille du fichier est: 38
a = 1
b = 1
c = 1
256087
256256
256512
256768
257024
257280
Lecture
#include<iostream>
#include<fstream>
#include<string>
using namespace std;
int main() {
string line;
ifstream f("poeme.txt");
if (!f.is_open()){
cout << "Impossible d'ouvrir le fichier en lecture\n";
return -1;
}
while (getline(f, line)) {
cout << line << "\n";
}
f.close();
return 0;
}
output:
demain dès l'aube à l'heure où blanchit la campagne
je partirai vois-tu je sais que tu m'attends
j'irai par la forêt j'irai par la montagne
je ne puis demeurer loin de toi plus longtemps
Traitements d’erreurs
Pour tous les flux (fichier, écran/clavier, mémoire), le traitement d’erreurs est similaire. Il se base sur l’état du flux (ios_base::iostate) codé par 4 bits (flags):
- goodbit
- badbit
- failbit
- eofbit
On peut tester et manipuler l’état du flux avec les méthodes
- good() $ \Rightarrow $ Aucune erreur
- bad() $ \Rightarrow $ Impossible d’extraire des données du flux
- fail() $ \Rightarrow $ Echec de l’opération
- eof() $ \Rightarrow $ Fin de fichier
- clear() $ \Rightarrow $ Réinitialisation des bits d’état
Méthodes de lecture d’istream
Lecture formatée
istream& operator>>(var)
cin >> var >> var2;
Lecture non formatée
- get() $ \Rightarrow $ lecture d’un seul char
- getline() $ \Rightarrow $ lecture d’une suite de char
- ignore() $ \Rightarrow $ ?
- peek() $ \Rightarrow $ donne le prochain char sans l’extraire
- seekg() $ \Rightarrow $ positionnement sur un flux
- read() $ \Rightarrow $ lecture de n char
Méthodes d’écriture d’ostream
Lecture formatée
ostream& operator<<()
cout << "PI=" << 3.14;
Écriture non formatée
- put() $ \Rightarrow $ écriture d’un seul char
- wirte() $ \Rightarrow $ écriture du contenu d’un tampon
- flush() $ \Rightarrow $ vidage de tampon
- tellp() $ \Rightarrow $ positionnement courant sur le flux
- seekp() $ \Rightarrow $ positionnement sur un flux
3. Le flux string
- La source ou la destination d’un flux peut être une string
- Point commun: les deux sont constitués d’octets
- Intérêt: Conversion, transferts en mémoire (buffers)
#include <sstream> $ \Rightarrow $ 3 classes:
- istringstream $ \Rightarrow $ Entrée
- ostringstream $ \Rightarrow $ Sortie
- stringstream $ \Rightarrow $ Les deux
La classe string
La STL impémente une classe string:
#include<string> // permet d'utiliser la classe std::string
Il s’agit en fait d’une classe qui est la spécialisation d’un template dont la définition (dans <string>) est:
typedef basic_string<char> string;
Avantages:
- plus simple et plus sûr que
char* - Définition de meethodes et opérateurs utiles
Méthodes usuelles de string
Opérateurs:
- Affectation
= - Concaténation
+=,+ - Comparaisons
==,<,>,<=,>=
Méthodes:
int size ()$ \Rightarrow $ Renvoie le nombre de caractèresint lenght ()$ \Rightarrow $ Renvoie le nombre de caractèresint capacity ()$ \Rightarrow $ taille possible sans la réallocationbool empty ()$ \Rightarrow $truesi la string est videfauxsinon.int find ()$ \Rightarrow $ position de la stringsdans la string courante à partir deposstring substr(int start, int lenght)$ \Rightarrow $ Sous string de longueurlenghtà partir destart
Les comparaisons de strings sont faites dans l’odre lexicographique (comme un dictionnaire) et sont sensibles à la casse.
Conversion de string (sans flux)
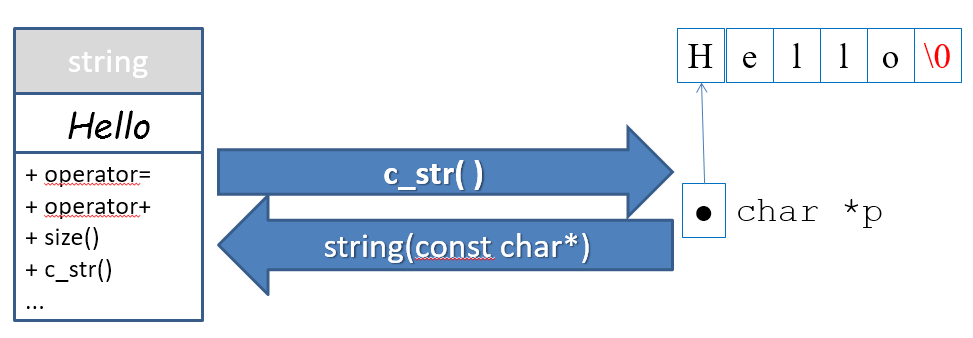
#include<iostream>
#include<cstdio>
#include<string>
using namespace std;
int main() {
const char* p = "Hello";
std::string s(p);
std::string s2("--");
std::string s3 = "World";
std::cout << s << s2 << s3 << std::endl;
const char *p2;
p2 = s3.c_str();
printf("%s %s!\n", p, p2);
return 0;
}
Conversions en type numériques
COMPLÉTER
Voir cheatSheet sur la programmation sockets
atoi()atol()atod()itoa()
Conversion avec les flux de string
#include<iostream>
#include<sstream>
int main() {
std::ostringstream a;
a << 10;
std::string b = a.str();
// Type => string
// - envoyer dans le flux
// - méthode str()
std::istringstream c("10");
int nb;
c >> nb;
// string => type
// - créer flux de la chaîne
// - extraire du flux vers la var
return 0;
}
4. vue d’ensemble
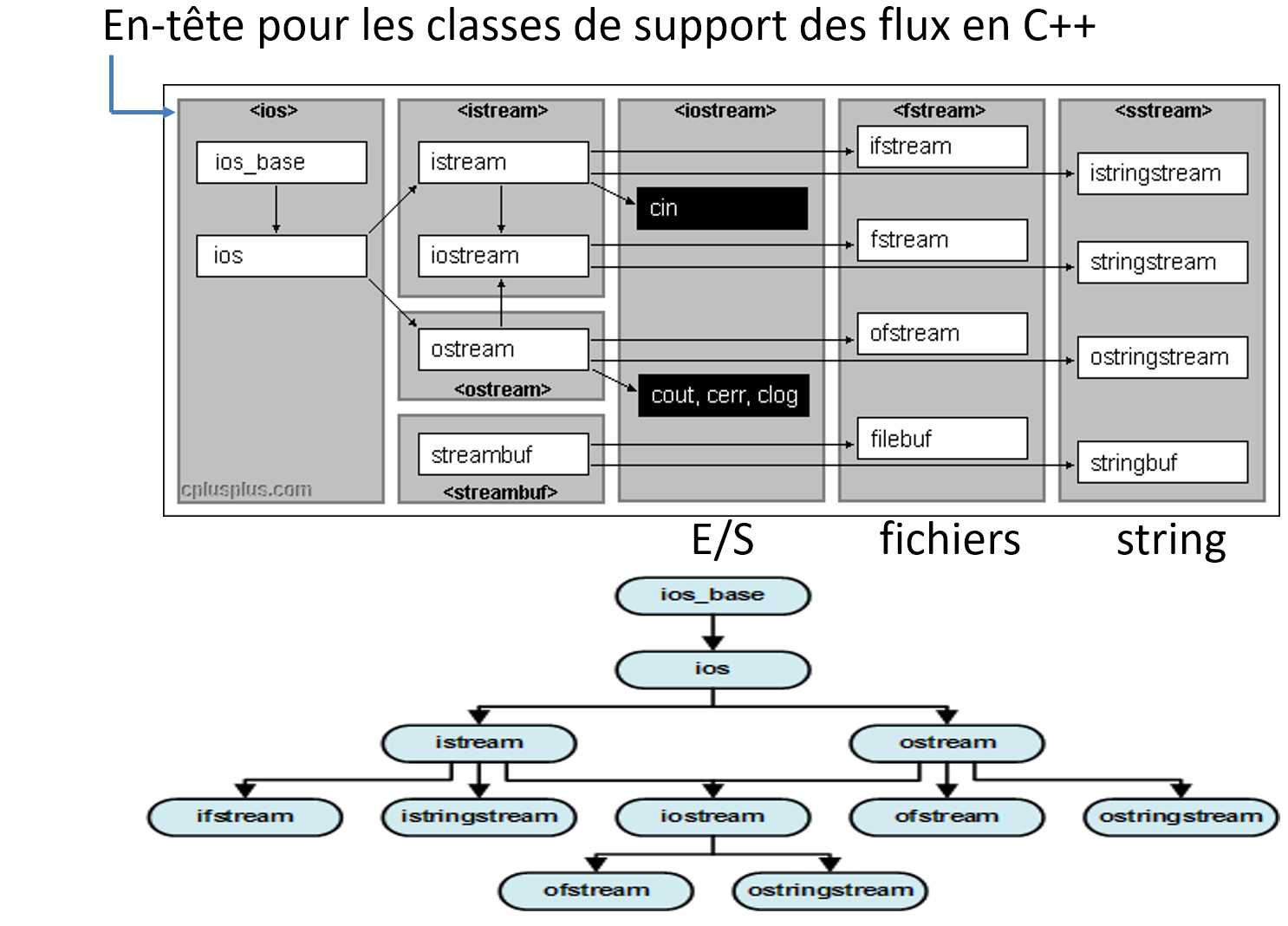
Les classes du bus sont probablement
fstreametstringstreamcar à la fois input et output (erreur sur la figure)
5. Standard Template Library (STL)
Bibliothèque de structures de données classiques et les algorithmes associés intégrée à la procédure de standardisation de C++. Basée sur des templates de classes, elle contient:
- Conteneurs
- Séquentiels
- Associatifs
- Itérateurs
- Algorithmes
- Objets fonctions (foncteurs à creuser )
- Adaptateurs
- Allocateurs
Un foncteur est une entité qui peut être appelée comme un fonction. Un objet d’uneclasse dans laquelle on a défini une surcharge de l’opérateur () est également un foncteur.
Un conteneur (container) est, comme son nom l’indique, un objet qui contient d’autres objets. Il fournit un moyen de gérer les objets contenus (au minimum ajout / supression, parfois insertion, tri, recherche,…) ainsi qu’un accès à ces objets qui dans le cas de la STL consiste très souvent en un iteerateur.
Les itérateurs permettent de parcourir une collection d’objets sans avoir à se préoccuper de la manière dont ils sont stockés. Ceci permet aussi d’avoir une interface de manipulation commune, et c’est ainsi que la STL fournit des algorithmes génériques qui s’appliquent à la majorité de ses conteneurs (tri,recherche, …).
Parmi les conteneurs disponibles dans la STL on retrouve les tableaux (vector), les listes (list), les ensembles (set), les piles (stack) et beaucoup d’autres.
Les classes conteneurs
Un conteneur est un objet qui permet de stocker d’autres objets.
-
Permet de gérer les objets contenus: ajout, supression (éventuellement insertion, tri, recherche)
-
Permet d’accéder aux objets contenus grâce aux itérateurs
-
Les itérateurs permettent de parcourir une collection d’objets sans avoir à se préoccuper de l’implémentation*. Ceci permet d’avoir une interface de manipulation commune, pour les algorithmes génériques de la STL (tri, recherche, remplacement,…)
Il existe deux types de conteurs:
séquentiels
Les éléments sont ordonnés. On peut parcourir le conteneur suivant cet ordre et insérer ou supprimer un élément en un endroit explicitement choisi;
Vecteur, liste, pile, file
Associatifs
Ce sont des conteneurs dont les éléments sont identifiés par une clé et ordonnés suivant celle-ci. Pour insérer un élément, il n’est en théorie plus utile de préciser un emplacement
dictionnaire, map
Conteneurs de séquences
*<vector> $ \Rightarrow $ tableau dynamique contigu
*<array> $ \Rightarrow $ tableau statique contigu
*<deque> $ \Rightarrow $ File à double entrée
*<list> $ \Rightarrow $ Liste doublement chainée
*<forward_list> $ \Rightarrow $ Liste simplement chainée
*<queue> $ \Rightarrow $ File
*<priority_queue> $ \Rightarrow $ File
*<stack> $ \Rightarrow $ Pile
Méthodes courantes des conteneurs
clear()$ \Rightarrow $ Vide le conteneursize()$ \Rightarrow $ Retourne le nombre d’élémentsempty()$ \Rightarrow $ Teste si le conteneur est videpush_back()$ \Rightarrow $ Ajoute un élément à la finpush_front()$ \Rightarrow $ Ajoute un élément au débutfront()$ \Rightarrow $ Renvoie le 1er élémentpop_front()$ \Rightarrow $ Supprime le premier élémentinsert()$ \Rightarrow $ Insère un élément quelconqueerase()$ \Rightarrow $ Supprime un élément
Exemple de conteneur séquentiel: vector
#include<iostream>
#include<vector>
#include<string>
using namespace std;
int main() {
vector<string> vect;
vect.push_back("introduction");
vect.push_back("une phrase");
vect.push_back("conclusion");
for (int i = 0; i < vect.size(); ++i) {
cout << vect[i] << endl;
}
return 0;
}
Exemple de conteneur séquentiel: list
#include<iostream>
#include<list>
using namespace std;
int main() {
list<int> lst;
lst.push_back(1); // 1
lst.push_front(0); // 0 1
lst.insert(lst.begin(), 2); // 2 0 1
lst.insert(lst.end(), 3); //2 0 1 3
lst.pop_front(); // 0 1 3
return 0;
}
Exemple de conteneur séquentiel: array
#include<iostream>
#include<array>
using namespace std;
int main() {
array<int, 3> a1 { {10, 11, 12} }; // uniform init
array<int, 3> a2 = {10, 11, 12}; // cstr de copie ou cstr
for (int i = 0; i < a1.size(); ++i) {
cout << a1[i] << endl; // deux accesseurs
cout << a1.at(i) << endl; // PAS equivalents
}
return 0;
}
#include<iostream>
#include<array>
using namespace std;
int main() {
array<int, 3> a1{ {10, 11, 12} };
// accès sans test. Affiche une
// valeur quelconque
cout << a1[-1] << endl;
// Lève une exception: out_of_range
// what() -> array:at
cout << a1.at(-1) << endl;
return 0;
}
La lasse array a des méthodes:
-
size()$ \Rightarrow $ plus besoin de passer un paramètre de taille aux fonctions ou utilisersizeof(tab)/sizeof(int)par exemple. -
Les accès par la méthode
at(indice)sont sécurisés par des Exceptions.
Destruction d’un objet conteneur
Quand est il nécéssaire d’éffacer ce qui est stocké dans un vecteur?
La réponse dépend de la nature de ce qui est stocké:
-
Si il s’agit d’un objet, il n’est pas utile de le détruire, il le sera lors de son retrait (pop), ou lorsque le vecteur sera détruit.
-
Par contre, si il s’git d’un pointeur sur un objet, il faut le détruire sinon le programme présentera une fuite de mémoire.
Imbrication de conteneurs
Il est possible d’imbriquer les conteneurs de la STL. On peut ainsi, par exemple créer un vecteur de listes de strings par exemple (une chanson mémorisée dans un vecteur de couplets. Chaque couplet étant une liste de phrases):
vector< list< string>> maChanson;
La définition d’un type intermédiaire peut augmenter la lisibilité:
typedef list<string> Couplet;
vector<Couplet> maChanson;
Des objets vector imbriqué simulent des tableux multidimentionnels. On peut initialiser une matrice identité $m_{5 \time 5}$ avec le code suivant:
#include<iostream>
#include<vector>
using namespace std;
typedef vector<float> Ligne;
typedef vector<Ligne> Matrice;
int main() {
Matrice m{5}; // 5 lignes de largeur 0
for (int i = 0; i < 5; ++i) {
m[i].resize(5); // fixe la longueur des lignes à 5
for (int j = 0; j < 5; ++j) {
if (i == j) { m[i][j] = 1; }
else { m[i][j] = 0; }
}
}
return 0;
}
6. Les itérateurs
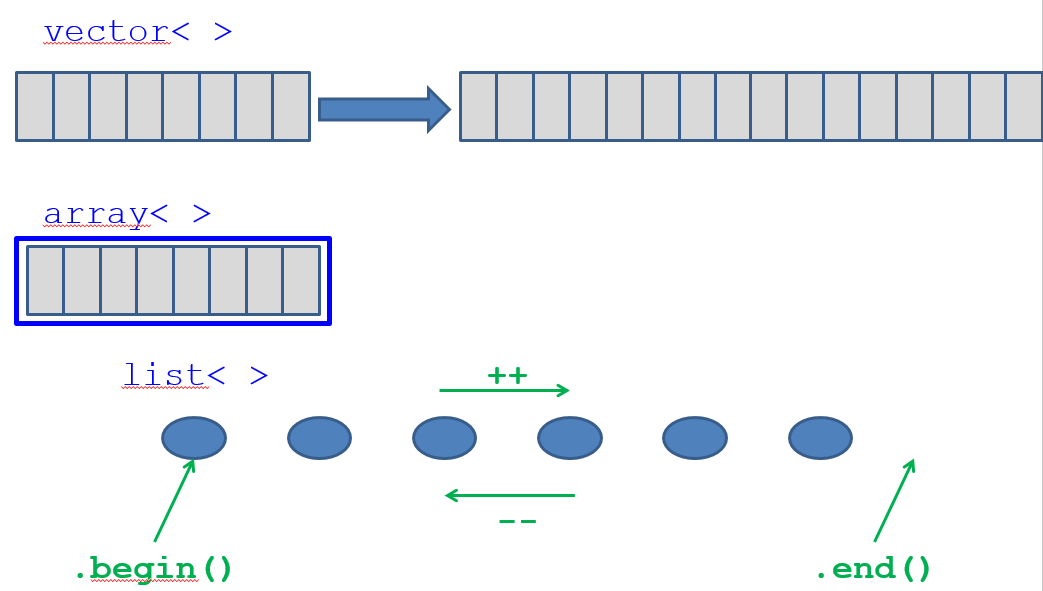
- Les itérateurs sont une généralisation des pointeurs
- ils permettent d’utiliser de façon uniforme divers conteneurs
- ils permettent de spécifier une position à l’intérieur d’un conteneur. Ils peuvent être incrémentés et déréférencés (avec
*) et deux itérateurs peuvent être comparés. - Tous les conteneurs disposent des méthodes:
begin()$ \Rightarrow $ Renvoie un itérateur pointant sur le premier élément.end()$ \Rightarrow $ renvoie un itérateur pointant arpès le dernier élément
On ne peut pas déréférencecr l’itérateur renvoyé par la méthode
end()
Ancienne syntaxe de déclaration:
container<type>::iterator nom;
vector<double>::iterator it
Un itérateur peut s’initialiser grâce aux méthodes begin, end ou find (containers non-séquentiels)
vector<double>::iterator it(vect.begin());
Syntaxe C++11
auto itr = vect.begin()
Exemple d’itérateur sur une liste
#include<iostream>
#include<list>
using namespace std;
int main() {
list<int> lst = {1,6,5,3,9};
// ancienne syntaxe déclaration uniforme
for (list<int>::iterator it{lst.begin()}; it != lst.end(); ++it) {
cout << *it << endl;
}
// nouvelle syntaxe
for (auto it = lst.begin(); it != lst.end(); ++it) {
cout << *it << endl;
}
// nouvelle syntaxe déclaration uniforme
for (auto it{lst.begin()}; it != lst.end(); ++it) {
cout << *it << endl;
}
return 0;
}
Range based for loop
vector<int> vec;
vec.push_back(10);
vec.push_back(20);
for (auto const &x: vec) {
cout << x << endl;
}
7. Conteneurs associatifs
- dictionnaire $ \Rightarrow $
map,multimap - ensembles (listes ordonnée) $ \Rightarrow $
set,multiset - tableau de booléens (bitArray?) $ \Rightarrow $
bitset
Les tables associatives sont une généralisation des tableux: Les indices peuvent être non-entier.
- Tableau que l’on pourrait indicer par des chaînes de caractères et écrire par exemple
moyenne["informatique"] - On parle d’association clé-valeur
- Les tables associatives sont définies dans la bibliothèque
<map> - Elles nécessitent deux types pour leur déclaration: le type des clés (les index) et le type des éléments indéxés
// clé valeur
map<string, double> moyenneParBranche; // clé unique
multimap<string, double> noteS_parBranche; // clé dupliquée
#include<iostream>
#include<string>
#include<map>
using namespace std;
int main() {
map<string, double> moyenne;
moyenne["informatique"] = 5.5;
moyenne["physique"] = 4.5;
// parcours de tous les éléments
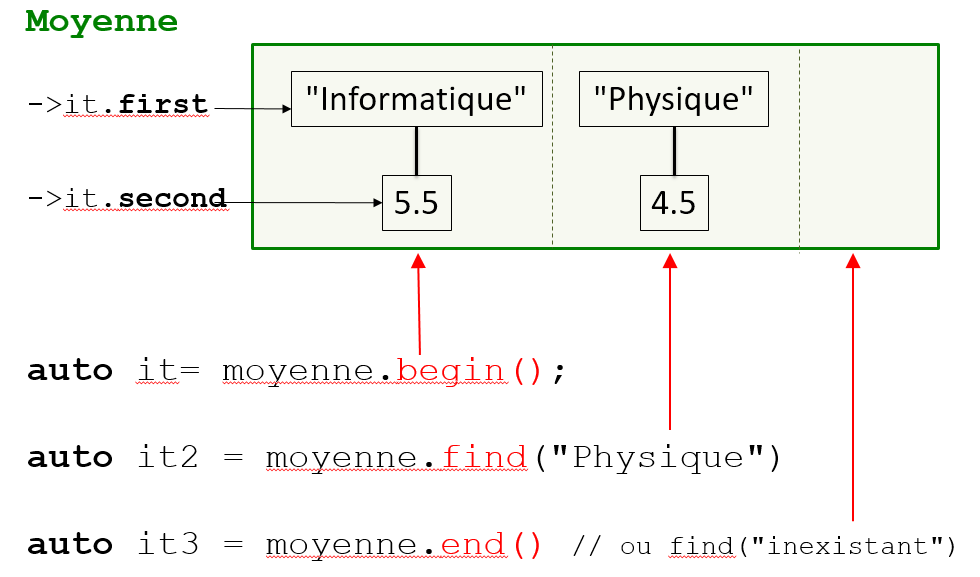
for (auto it = moyenne.begin(); it != moyenne.end(); ++it) {
cout << "En " << it->first << ", j'ai "
<< it->second << " de moyenne.\n";
}
// recherche
cout << "Ma moyenne en informatique est de ";
cout << moyenne.find("informatique")->second << endl;
// accès
auto it1 = moyenne.begin(); // 5.5
auto it2 = moyenne.find("Physique"); // 4.5
auto it3 = moyenne.end(); // ou moyenne.find("inexistant") => empty
return 0;
}
it.first$ \Rightarrow $ Donne accès à la cléit.second$ \Rightarrow $ Donne accès à la valeur
Attention!
- Le simple fait d’accéder à une clé via l’opérateur
[ ]insère cette clé (avec la donnéeT()) dans le conteneur map. - L’opérateur
[ ]n’est donc pas adapté pour vérifier si une clé est présente dans un conteneur de type map.
Il faut utiliser la méthode find()
std::pair<T1, T2>
Dans l’éxemple précédent, it est un itérateur. Si on déréférence it (*it) on accède à un élément qui est de type pair<const Key, T>
Une paire est une structure contenant deux éléments éventuellement de types différents. Certains algorithmes de la STP (find() par exemple) retournent des paires (position de l’élément trouvee et un booléen indiquant si il a été trouvé).
#include<iostream>
#include<string>
using namespace std;
int main() {
std::pair<int, std::string> p = std::make_pair(5, "poule");
cout << p.first << ' ' << p.second << endl;
return 0;
}
Exemple avec multimap
#include<iostream>
#include<map>
using namespace std;
int main() {
multimap<string, double> moyenne;
multimap<string, double> ::iterator it;
// les indices classiques ne fonctionnent pas avec les multimap !
// ils servent à l'affectation.
moyenne.insert(pair<string, double>("Informatique", 5.5));
moyenne.insert(pair<string, double>("Physique", 4.5));
// parcours de tous les éléments
for (it = moyenne.begin(); it != moyenne.end(); ++it)
cout << "En " << it->first << ", j'ai " << it->second <<
" de moyenne." << endl ;
return 0;
}
output:
En Informatique, j'ai 5.5 de moyenne.
En Physique, j'ai 4.5 de moyenne.
Afficher toutes les valeurs d’une même clé
#include<iostream>
#include<map>
using namespace std;
int main() {
multimap<string, double> moyenne;
moyenne.insert(pair<string, double>("Informatique", 5.5));
moyenne.insert(pair<string, double>("Physique", 4.5));
string recherche = "Physique";
multimap<string, double>::iterator it;
multimap<string, double>::iterator itlow;
multimap<string, double>::iterator itup;
itlow = moyenne.lower_bound(recherche);
itup = moyenne.upper_bound(recherche);
cout << recherche << "===>";
for (it = itlow; it != itup; ++it) {
cout << " " << (*it).second;
}
cout << endl;
return 0;
}
output:
Physique===> 4.5
Solution problème day 6 hackerRank (map)
#include<iostream>
#include<string>
#include<map>
using namespace std;
int main() {
int n;
string name;
int num;
cin >> n;
cin.ignore();
map <string, long> pBook;
for (int i = 0; i < n; i++) {
cin >> name;
cin >> num;
pBook[name] = num;
}
while(cin >> name) {
if (pBook.find(name) != pBook.end()) {
cout << name << "=" << pBook.find(name)->second << endl;
} else {
cout << "Not found" << endl;
}
}
return 0;
}
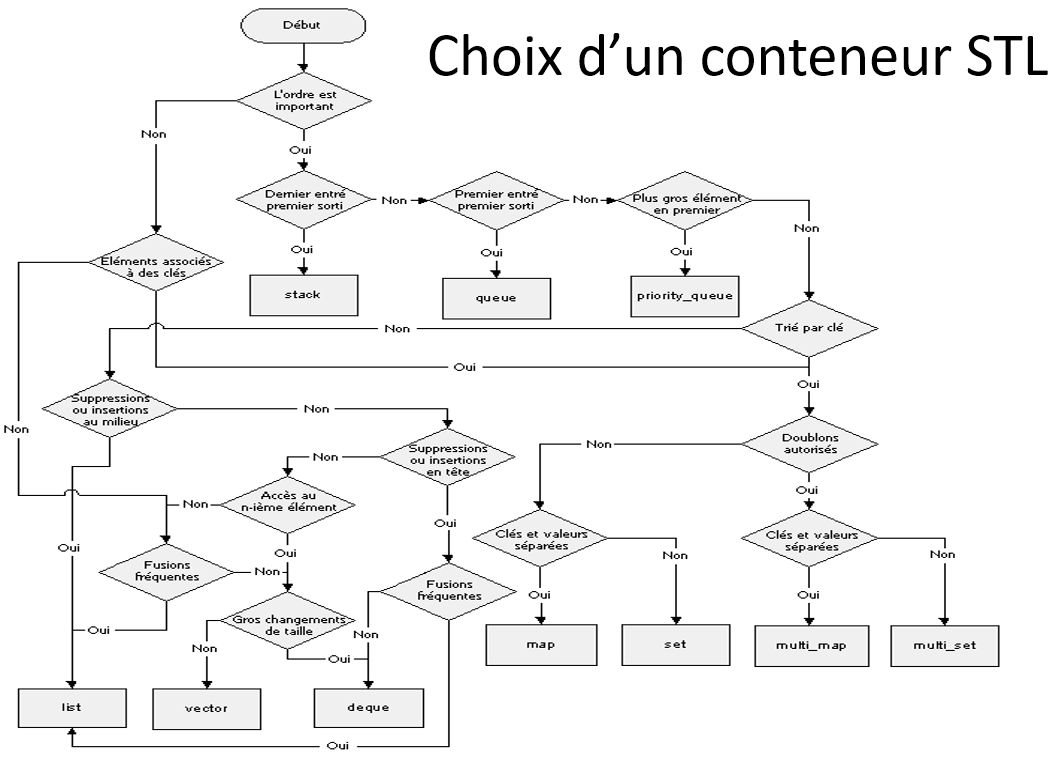
8. Choix d’un conteneur STL
9. Algorithmes de la STL
La plupart des traitements courants sur des structures de données sont implémentés de façon optimale c’est à dire que dans la grande majorité des cas il est préférable de les utiliser.
- ajouts, suppression, copies, déplacements, remplacements
- traitements sur chaque élément
- recherches
- comptages
- tris
10. Forme canonique d’une classe
La forme canonique (de Coplien) fournit un cadre à respecter pour les classes ayant des attributs alloués dynamiquement. Une classe T est dite sous forme canonique (ou fome normale, forme standard) si elle possède:
- un constructeur par défaut
- un constructeur de copie
- un destructeur
- un opérateur d’affectation surchargé
Pour utiliser les conteneurs ou algorithmes, la classe doit être canonique et implémenter l’opérateur de comparaison ==
Si la notion d’ordre est nécessaire, la clsse devra également implémenter l’opérateur <
11 Exemples pratiques
Vector
#include<iostream>
#include<vector>
using namespace std;
typedef vector<int> Tableau;
void f(Tableau &tab1, Tableau &tab2) {
for (int i = 0; i < tab1.size(); ++i) {
tab2.push_back(tab1.front());
}
}
int main() {
// a)
{
cout << "exercice a)\n";
Tableau tab;
for (int i = 0; i < 10; ++i) {
tab.push_back(tab.size());
}
for (const auto &x: tab) { cout << x << " "; }
// tab1 {0,1,2,3,4,5,6,7,8,9}
}
// b)
{
cout << "\nexercice b)\n";
Tableau tab1, tab2;
tab1.push_back(0);
f(tab1, tab2);
for (const auto &x: tab2) { cout << x << " "; }
// tab2 {0,0,0,0,0,0,0,0,0,0}
cout << endl;
}
// c)
{
cout << "\nexercice c)\n";
Tableau tab;
int loop = 0;
cout << tab.max_size() << endl; // 4 611 686 018 427 387 903
try
{
// for (unsigned int i = 0; i < tab.max_size()/8 + 1; ++i) {
// tab.push_back(i);
// ++ loop;
// }
}
catch (bad_alloc &e)
{
cout << "Erreur: " << e.what() << endl;
}
cout << "Loop: " << loop << endl;
// sous reserve d'avoir assez de mémoire une exception de type
// bad_alloc est levée
}
// d)
{
cout << "\nexercice d)\n";
Tableau tab(3,11); // => {11,11,11}
Tableau tab2{3,11}; // => {3,11}
for (const auto &x: tab) { cout << x << " "; }
cout << endl;
tab[4] = 3; // rien ne se passe, même pas d'erreur pourtant
// il y a débordement => DANGEREUX
for (const auto &x: tab) { cout << x << " "; } // 3 éléments affiché
cout << endl << tab[4] << endl; // sous reserve que ça ne crache pas, retourne 3
cout << "\n exercice e)\n";
try
{
cout << "tab.at(tab.size()) : " << tab.at(tab.size()) << endl;
}
catch (out_of_range &e)
{
cout << "\n Erreur : " << e.what() << endl;
} // Erreur : vector::_M_range_check: __n (which is 3) >= this->size() (which is 3)
}
return 0;
}
output:
exercice a)
0 1 2 3 4 5 6 7 8 9
exercice b)
0
exercice c)
4611686018427387903
Loop: 0
exercice d)
11 11 11
11 11 11
3
exercice e)
tab.at(tab.size()) :
Erreur : vector::_M_range_check: __n (which is 3) >= this->size() (which is 3)
size, capacity et max_size
#include<iostream>
#include<vector>
#include<windows.h> // Sleep
#include<stdlib.h> // system
using namespace std;
int main () {
vector<int> myvector;
// set some content in the vector:
for (int i=0; i<100; i++) {
Sleep(200);
system("cls");
myvector.push_back(i);
cout << "i: " << i << "\n";
cout << "size: " << (int) myvector.size() << "\n";
cout << "capacity: " << (int) myvector.capacity() << "\n";
cout << "max_size: " << (int) myvector.max_size() << "\n\n";
}
return 0;
}
output:

sizeest le nombre d’éléments dans le tableaucapacityest le nombre total d’éléments qu’il est possible d’introduire dans le tableau sans faire une nouvelle réallocation de mémoiremax_sizeest le nombre maximal d’éléments que peut avoir un conteneur
multimap
#include<iostream>
#include<string>
#include<map>
using namespace std;
// affiche tous les éléments du dico
template<typename Key, typename Val>
void showMultimap(const multimap<Key, Val> &m) {
//typename multimap<Key, Val>::const_iterator it;
for (auto it = m.begin(); it != m.end(); ++it) {
cout << it->first << "\t" << it->second << endl;
}
cout << endl;
}
// affiche les éléments du dico dont la clé est "find"
template<typename Key, typename Val>
void showMultimapRange(const multimap<Key, Val> &m, const Key &find) {
auto itlow = m.lower_bound(find);
auto itup = m.upper_bound(find);
cout << find << " ==>";
for (auto it = itlow; it != itup; ++it) {
cout << " | " << it->second;
}
cout << endl;
}
int main() {
multimap<string, string> pays;
pays.insert(pair<string,string>("CH", "Berne"));
pays.insert(pair<string,string>("BE", "Nivelles"));
pays.insert(pair<string,string>("BE", "Liege"));
pays.insert(pair<string,string>("BE", "Mons"));
showMultimap(pays);
string s = "BE";
showMultimapRange(pays, s); // showMultimapRange(pays, "BE")
// ne fonctionne pas !
showMultimapRange(pays, (string) "BE"); // on doit cast !
return 0;
}
}
}
output:
BE Nivelles
BE Liege
BE Mons
CH Berne
BE==> | Nivelles | Liege | Mons
BE==> | Nivelles | Liege | Mons
Ecrire un programme qui lise un fichier de texte donné en paramètre, complètement, mot par mot. Le programme créera une table associative (dictionnaire clé-valeur) avec comme clés les mots, et comme valeur le nombre d’occurrences. A la fin de l’exécution, le programme affichera le nombre total de mots contenu dans le texte, le nombre de mots différents, ainsi que le nombre d’occurrences de chaque mot.
poeme.txt:
demain des l'aube a l'heure ou blanchit la campagne
je partirai vois-tu je sais que tu m'attends
j'irai par la foret j'irai par la montagne
je ne puis demeurer loin de toi plus longtemps
#include<iostream>
#include<fstream>
#include<string>
#include<vector>
#include<map>
using namespace std;
const string file = "poeme.txt";
void fillWordVec(ifstream&, vector<string>&);
void factor(vector<string>&, string&);
bool fillDict(multimap<string, int>&, const string&);
int main() {
ifstream f(file);
vector<string> all;
multimap<string, int> dict;
if (!f.is_open()){
cout << "Impossible d'ouvrir le fichier en ecriture\n";
return -1;
}
// split le fichiers en vecteur de mots
fillWordVec(f, all);
// remplit le dictionnaire
for (const auto& x: all) {
if(!fillDict(dict, (string) x)) {
dict.insert(pair<string, int>((string) x,1));
}
}
// display
cout << "Le fichier contient " << all.size() << " mots\n";
cout << "il y a " << dict.size() << " mots différents\n";
cout << "nombre d'occurences de chaque mot:\n";
// affiche occurences de chaque mot:
for (const auto& x: dict) {
cout << x.second << "x \"" << x.first << "\"\n";
}
// idem
// for (auto it = dict.begin(); it != dict.end(); ++it) {
// cout << it->second << "x \"" << it->first << "\"\n";
// }
f.close();
return 0;
}
void fillWordVec(ifstream &f, vector<string> &vec) {
string word, line;
while (getline(f, line)) {
if (!line.empty()) {
for (int i = 0; i < line.size(); ++i) {
if (line[i] == ' ' || line[i] == '\'' || line[i] == '-') {
++i;
factor(vec, word);
}
word += line[i];
}
factor(vec, word);
}
}
}
void factor(vector<string> &vec, string &word) {
vec.push_back(word);
word.clear();
}
bool fillDict(multimap<string, int> &m, const string &find) {
bool flag = false;
auto itlow = m.lower_bound(find);
auto itup = m.upper_bound(find);
for (auto it = itlow; it != itup; ++it) {
flag = true;
++(it->second);
}
return flag;
}
output:
Le fichier contient 40 mots
il y a 31 mots différents
nombre d'occurences de chaque mot:
1x "a"
1x "attends"
1x "aube"
1x "blanchit"
1x "campagne"
1x "de"
1x "demain"
1x "demeurer"
1x "des"
1x "foret"
1x "heure"
2x "irai"
2x "j"
3x "je"
2x "l"
3x "la"
1x "loin"
1x "longtemps"
1x "m"
1x "montagne"
1x "ne"
1x "ou"
2x "par"
1x "partirai"
1x "plus"
1x "puis"
1x "que"
1x "sais"
1x "toi"
2x "tu"
1x "vois"