introduction à NumPy et MatPlotLib
Directory
CheatSheet
numpy¶
Importer numpy¶
- par convention
numpyest utilisé via l'aliasnp - cela permet de prefixer les fonctions de la librairie en utilisant
np.à la place denumpy.
import numpy as np
Arrays¶
- les Arrays représentent une collection de valeurs
contrairement aux listes:
les arrays ont une taille fixe
- elles peuvent être resize mais cela implique la recopie de l'array
toutes les valeurs ont le même type
- typiquement des floats
tout comme les listes:
- les arrays sont mutables
- on peut changer les éléments d'un array
Arrays de numpy¶
- les array sont fourni par le module
numpy - la fonction
array()crée et arrange une liste donnée
import numpy as np
x = np.array([0, 1, 2, 3, 4])
x
Affichage¶
- la fonction
print()nous donne un pretty display
print(x)
- l'utilisation du nom de la variable (dans la console uniquement) nous donne un affichage qui nous permet de différencier les array des listes classiques
x
Indexe¶
- on peut utiliser les indexes de la même façon que pour une liste
x[4]
x[4] = 2
x
Les arrays ne sont pas des listes¶
- même si ça y ressemble, les array sont une structure de donnée fondamentalement différente:
type(x)
- par exemple, on ne peut pas utiliser des methodes comme
append()
x.append(5)
Utilisation de fonctions sur des Arrays¶
- Si on utilise des opérateurs arithmétiques sur des arrays, on crée un nouvel array auquel, sur chaque élément, a été appliqué l'opérateur
y = x * 2
y
- même chose pour les fonctions
x = np.array([-1, 2, 3, -4])
y = abs(x)
y
peupler les Array¶
- pour peupler un array avec un range de valeurs, on utilise la fonction
np.arange()
x = np.arange(0,10)
print(x)
- on peut utiliser une incrémentation float
x = np.arange(0,1,0.1)
print(x)
x
Vectorisation de fonctions¶
- toutes les fonctions ne fonctionnent pas automatiquement avec les arrays
- les fonctions qui fonctionnes avec les arrays sont dites vectorisées
- la majorité des fonctions de
numpysont vectorisées - on peut définir des fonctions vectorisées nous même (un peu comme la surcharge en C++) grâce a la fonction supérieure
numpy.vectorize()
def myfunc(x):
if x >= 0.5:
return x
else:
return 0.0
fv = np.vectorize(myfunc)
x = np.arange(0, 1, 0.1)
x
fv(x)
import matplotlib.pyplot as plt
# uniquement nécéssaire pour Jupyter
%matplotlib inline
y = x*2 + 5
plt.plot(x, y)

Plot d'une sin¶
from numpy import pi, sin
x = np.arange(0, 2*pi, 0.01)
y = sin(x)
plt.plot(x, y)

Données multidimensionnelles¶
- les arrays de numpy peuvent contenir des données multidimensionnelles
- pour créér un array multidimensionnel, nous pouvons passer une liste de listes à la fonction
array()
import numpy as np
x = np.array([[1, 2], [3, 4]])
x
Array d'arrays¶
- un array multidimensionnel est un array d'array
- l'array extérieur contient les lignes
- chaque ligne est un array
x[0]
x[1]
- l'élément dans la seconde ligne et première colonne est:
x[1][0]
Matrices¶
- nous pouvons transformer un array multidimensionnel en matrice
M = np.matrix(x)
M
Plot multidimensionnel avec des matrices¶
- si nous utilisons
plot()pour ploter une matrice, ce dernier utilisera les valeurs de l'axe des y (colones de la matrice).
from numpy import pi, sin, cos
x = np.arange(0, 2*pi, 0.01)
y = sin(x)
ax = plt.plot(x, np.matrix([sin(x), cos(x)]).T)

Performance¶
- les matrices de
numpysont liées à des fonctions correspondantes écritent en C et FORTRAN - Ces librairies sont très rapides et peuvent être configurées de façon à ce que les opérations soient faites en parallèle sur plusieurs coeurs.
Opérations sur les matrices¶
- Une fois que nous avons une matrice nous pouvons lui appliquer des opérations spécifiques à ces dernières
- pour transposer et inverser on utilise respectivement les attributs T et I
import numpy as np
x = np.array([[1, 2], [3, 4]])
M = np.matrix(x)
M
Pour effectuer la transposition $M^T$:
M.T
Pour effectuer l'inversion $M^{-1}$:
M.I
Dimensions d'une matrice¶
- le nombre total d'éléments et les dimensions de la matrice:
M.size
M.shape
len(M.shape)
Créer une matrice à partir de strings¶
- nous pouvons aussi créér des matrices directement à partir de strigs:
I2 = np.matrix('2 0; 0 2')
I2
- le point virgule (;) marque le début d'une nouvelle ligne
Multiplication de matrices¶
- maintenant que nous avons deux matrices, nous pouvons les multiplier:
M * I2
Indexes et matrices¶
- nous pouvons utiliser les indexes et même slicer une matrices en utilisant la même syntaxe que pour les listes
M[:,1]
Les slices sont des références¶
- de la façon suivante, on crée une référence à l'élément slicé et non pas une copie
V = M[:,1] # ne crée pas une copie des éléments mais référence l'objet initial !
V
M[0,1] = -2
V
Copier des matrices et des vecteurs¶
- pour copier une matrice ou une slice de ses éléments, on utilise la fonction
np.copy()
M = np.matrix('1 2; 3 4')
V = np.copy(M[:,1]) # copie des éléments
V
M[0,1] = -2
V
Somme¶
- une façon de faire la sommer un vecteur ou une matrice est via une boucle
for
vector = np.arange(0.0, 100.0, 10.0)
vector
result = 0.0
for x in vector:
result += x
result
- ce n'est pas une façon éfficace d'effectuer une somme
Somme efficace¶
- à la place de la boucle
fornous pouvons utiliser la fonctionsum() - cette fonction est écrite en C et est beaucoup plus performante
vector = np.array([0, 1, 2, 3, 4])
print(np.sum(vector))
Somme des lignes / colones¶
- quand nous avons affaire à des données multidimensionnelles, la fonction
sum()possède un argument axis qui ne permet de spécifier si nous désirons la somme des lignes ou des colonnes
matrix = np.matrix('1 2 3; 4 5 6; 7 8 9')
print(matrix)
- somme des lignes
np.sum(matrix, axis=0)
- somme des colonnes
np.sum(matrix, axis=1)
Sommes cumulatives¶
x = np.matrix('1 2 3; 4 5 6; 7 8 9')
print(x)
y = np.cumsum(x)
print(np.cumsum(x, axis=0))
print(np.cumsum(x, axis=1))
Produit cumulé¶
- de façon similaire, nous pouvons calculer $\large{y_n = \Pi^{n}_{i-1}{x_i}}$ en utilisant
cumprod()
import numpy as np
x = np.array([1, 2, 3, 4, 5])
print(np.cumprod(x))
- nous pouvons calculer le produit cummulatif entre les lignes et les colonnes en utilisant le paramètre axis.
Génération de nombres pseudo aléatoires¶
- le sous module
numpy.randomcontient des fonctions pour générer des nombres aléatoires
from numpy.random import normal, uniform, exponential, randint
- supposons que nous avons une variable aléatoire $\large{\epsilon \sim N(0,1)}$
- dans Python nous pouvons utiliser cette distribution de la façon suivante:
epsilon = normal()
print(epsilon)
- chaque appel de cette variable nous retournera la même valeur
print(epsilon)
- si nous appellons encore une fois la fonction, celà va nous retourner un nouveau draw de cette distribution:
epsilon = normal()
print(epsilon)
Nombres pseudo-aléatoires¶
- en réalité ces nombres ne sont pas des nombres aléatoires
- ils sont basés sur un état initial appelé seed
- si nous connaissons le seed, nous pouvons prédire précisément le reste de la séquence à partir de n'importe quel nombre "aléatoire".
- cela dit, statistiquement parlant ces nombres se comportent comme des nombres aléatoires
Gestion des seed¶
- dans certains cas nous avons besoin de pouvoir reproduir une séquence de nombres pseudo aléatoires
- nous pouvons spécifier la valeur du seed avant utilisation de ces nombres
- pour se faire on utilise la fonction
seed()dans le sous modulenumpy.random
from numpy.random import seed
seed(5)
normal()
normal()
seed(5)
normal()
normal()
Générer multiple¶
- pour se faire nous pouvons spécifier le paramétre
size:
normal(size=10)
Cette façon de procéder est BEAUCOUP plus rapide qu'une boucle for!
- nous pouvons également spécifier plus d'une dimension:
normal(size=(5,5))
Histogrammes¶
- pour ploter un histogramme de données distribuées aléatoirement, on utilise la fonction
hist()demtplotlib:
import matplotlib.pyplot as plt
%matplotlib inline
data = normal(size=10000)
ax = plt.hist(data)

Calculer les histogrammes en matrices¶
- la fonction
histogram()dans le modulenumpycompte les fréquences dans les plages et retourner le résultat sous forme d'array 2d:
import numpy as np
np.histogram(data)
Statistiques¶
- nous pouvons calculer les statistiques d'un sample de données en utilisant les fonctions de
numpymean()etvar()
np.mean(data)
np.var(data)
- ces fonctions ont aussi un paramètre
axispour calculer la moyenne d'arrays multidimensionnels.
Nombres aléatoires discrets¶
- la fonction
randint()du modulenumpy.randompeut être utilisé pour sortir des nombres aléatoires - il prend deux paramètres: valeur basse (inclus), et valeur haute (exclue)
- pour simuler un jet de dé:
die_roll = randint(0,6)+1
die_roll
Résumé
Numpy¶
Numpy est une librairie centrale pour le calcule scientifique en Python. Elle contient une collection d'outils qui permettent de résoudre et de modéliser des problèmes mathématiques, scientifiques et du domaine de l'ingénierie.
Le coeur de ces outils est une structure de données de type liste multidimentionnelle de haut performance qui se nome tout simplement Array (Numpy Array).
- Voici un exemple d'un array 2d dans Numpy:
import numpy
M = numpy.array([[1,2,3], [4,5,6]])
M
Performance¶
- les matrices de
numpysont liées à des fonctions correspondantes écritent en C et FORTRAN - Ces librairies sont très rapides et peuvent être configurées de façon à ce que les opérations soient faites en parallèle sur plusieurs coeurs.
Dimensions¶
Cette illustration représente les 3 premières dimensions de l'objet mathématique matrice
- axis 0 (idx[0]) axe des $\large x$
- axis 1 (idx[0][0]) axe des $\large y$
- axis 2 (idx[0][0][0]) axe des $\large z$
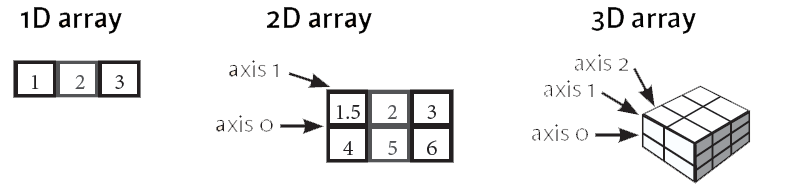
Et voici la représentation de matrices comme nous le print() Numpy
- matrice à une dimension:
- matrice à deux dimensions:
- matrice à trois dimensions:
Arrays¶
- les Arrays représentent une collection de données
contrairement aux listes:
les arrays ont une taille fixe
- elles peuvent être resize mais cela implique la recopie de l'array
c'est une collection homogène (toutes les données ont le même type)
- typiquement des floats
tout comme les listes:
- les arrays sont mutables (on peut changer les éléments d'un array)
Numpy permet de créer plusieurs types d'arrays. On appelle:
- vecteur un array 1d
- matrice un array multi d. (fondamentalement c'est un vecteur aussi)
L'implémentation des Numpy Arrays possède 4 pointeurs importants:
- data pointe sur l'adresse du premier byte de l'array
- dtype pointe sur une représentation du type de donnès que contient la collection
- shape pointe sur une représentation de la forme de l'array (tuple dont le nombre d'éléments représente le nombre de dimensions et la clé des éléments la taille de cette dimension)
- strides pointe sur une représentation du nombre de bytes qui doivent être sauté en mémoire pour arriver au prochain élément. Si l'objet retourné est par exemple (10,1) ont doit sauter 1 byte pour passer à la colonne suivante et 10 bytes pour sauter à la ligne suivante.
En somme, un array contient des informations concernant les raw data (données en elles mêmes) mais aussi sur comment interpréter ces données.
print("représentation: \n", M,"\n")
print("pointeur data: \t", M.data)
print("pointeur type: \t", M.shape)
print("pointeur shape: \t", M.dtype)
print("pointeur strides:\t", M.strides)
Les arrays possèdent des methodes qui nous permettent d'inspecter notre array voici celles qui peuvent être uttile à ce niveau:
- .ndim retourne le nombre de dimensions
print(M.ndim)
- .size retourne le nombre d'éléments
print(M.size)
- .flags retourne des informations utiles sur la gestion de la mémoire
print(M.flags)
- .itemize retourne le poids d'un élément de l'array en bytes
print(M.itemsize)
- .nbytes retourne le poids total en bytes de l'array
print(M.nbytes)
Création d'arrays¶
- par convention
numpyest utilisé via l'aliasnp - cela permet de prefixer les fonctions de la librairie en utilisant
np.à la place denumpy.
import numpy as np
Creation d'array 1d¶
- conversion de listes classiques en array
a = [1,3,5,7,9]
print(type(a))
print(a)
b = np.array(a)
print(type(b))
print(b)
- création directe d'array
a = np.array([1,3,5,7,9], dtype=np.int64)
print(a)
print(a.dtype)
- il n'est pas obligatoire de spécifier le type de données par défaut ce sont des int32
b = np.array([1,3,5,7,9])
print(b)
print(b.dtype)
Création de matrices (multi d.)¶
- conversion de liste 2d en matrice
l = [[1,2,3], [4,5,6], [7,8,9]]
A = np.array(l)
print(A)
- création directe de matrice
B = np.array([[1,2,3], [4,5,6], [7,8,9]])
print(B)
Création d'array "vides" et peuplement d'array¶
Parfois on ne sait pas d'avance la valeurs des données que contiendra notre array où ces données seront importé d'une autre source. Dans ce cas on initialisera l'array respectivement avec des des placeholders "vides" ou nous utiliserons des fonctions pour charger les données à partir de fichiers textes. Un array vide est un array qui ne contient que des $1$ ou des $0$ qui sont les placeholders qui seront remplis par la suite.
ones(shape, dtype=None)¶
- matrice 2d remplie de $1$ (si nous ne spécifions pas le type, par défaut la methode
onesinitialise avec des floats64)
a = np.ones((3,4))
print(a)
print(a.dtype)
a = np.ones((3,4), dtype=np.int32)
print(a)
print(a.dtype)
zeros(shape, dtype=float)¶
- matrice 3d de 0
b = np.zeros((2,3,4), dtype=np.int32)
print(b)
empty(shape, dtype=float)¶
- matrice 2d "vide" d'un certain type (par défaut float64)
c = np.empty((3,2), dtype=np.int32)
print(c)
print(c.dtype)
random(shape)¶
- matrice 2d remplie avec des valeurs aléaoires (pas de paramètre dtype)
d = np.random.random((3,2))
print(d)
print(d.dtype)
- matrice 2d remplie avec des valeurs aléatoires dans un range
d = np.random.uniform(low=0, high=30, size=(3,2))
print(d)
- matrice 2d remplie avec des valeurs aléatoires (int) dans un range
d = np.random.randint(30, size=(4,2)).astype(np.int16)
print(d)
full(shape, fill_value, dtype=None)¶
- matrice 3d remplie avec une valeur spécifique (warning si on ne spécifie pas de dtype)
e = np.full((3,2,3),5, dtype=np.int32)
print(e)
print(e.dtype)
arange(start=None, stop, step=None, dtype=None)¶
- array 1d de valeurs espacées uniformément
f = np.arange(10,25,5)
print(f)
print(f.dtype)
- incrémentation à virgule flotante
f = np.arange(0,1,0.1)
print(f)
print(f.dtype)
linspace(start, stop, endpoint=True, retstep=False, dtype=None)¶
- array 1d de valeurs espacées uniformément
g = np.linspace(0,2,9)
print(g)
print(g.dtype)
arange() et linspace() nous permettent de peupler des arrays avec des valeurs espacées uniformément. La différence entre les deux est la signification du 3e paramètre passé en argument.
arange(): c'est le step qui désigne l'écart entre deux valeurslinspace()c'est le nombre de samples:
for i in range(7,0,-1):
print(np.linspace(0, 5, i, dtype=np.int32))
Création d'array et matrice "identité"¶
An identity matrix is a square matrix of which all elements in the principal diagonal are ones and all other elements are zeros. When you multiply a matrix with an identity matrix, the given matrix is left unchanged.
In other words, if you multiply a matrix by an identity matrix, the resulting product will be the same matrix again by the standard conventions of matrix multiplication.
eye(N, M=None, k=0, dtype=float)¶
- retourne une matrice 2d avec des $1$ sur la diagonale principale et les reste remplis avec des $0$
h = np.eye(3)
print(h)
print(h.dtype)
identity(n, dtype=None)¶
- retourne une matrice identité carrée (The identity array is a square array with ones on the main diagonal)
i = np.identity(4)
print(i)
print(i.dtype)
Remplir un array avec les valeurs d'un fichier¶
loadtxt()¶
fichier value.txt
# Value1 Value2 Value3
# 0.2536 0.1008 0.3857
# 0.4839 0.4536 0.3561
# 0.1292 0.6875 0.5929
# 0.1781 0.3049 0.8928
# 0.6253 0.3486 0.8791
x, y, z = np.loadtxt('C:/Users/sol.rosca/Jupyter_notbooks/value.txt',
skiprows=1,
unpack=True)
genfromtxt()¶
fichier value2.txt
# Value1 Value2 Value3
# 0.4839 0.4536 0.3561
# 0.1292 0.6875 MISSING
# 0.1781 0.3049 0.8928
# MISSING 0.5801 0.2038
# 0.5993 0.4357 0.7410
my_array = np.empty((3,7))
my_array = np.genfromtxt('C:/Users/sol.rosca/Jupyter_notbooks/value2.txt',
skip_header=1,
filling_values=-999)
loadtxt()charge les données dans notre environement.- le premier parmètre que prenne les deux fonctions est le path du fichier
value.txt. - ensuite viennent des arguments spécifiques au fonctions.
- le premier parmètre que prenne les deux fonctions est le path du fichier
- pour loadtxt() on passe la première ligne et on retourne les colonnes comme étant des arrays distincts avec l'argument
unpack=TRUE. Celà veut dire que les valeurs de la première colonne (value1) vont dans la variablexetc...
à noter que si nous avons des valeurs délimitées par des virgules, ou si nous voulons spécifier le type de données, il existe des arguments
delimiteretdtypequ'on peut ajouter àloadtxt()
genfromtxt()est utile dans le cas où nous avons à gérer un fichier où il manque des valeurs. Dans le cas présent, les valeurs manquantes sont marquées dans le fichier par string'MISSING'. Cette fonction, converti les valeurs par l'argument du paramètrefiling_valuesqu'on a ici set à la valeur -999.
Généralement la fonction genfromtxt() est plus flexible et plus robuste que loadtxt()et offre plus de possibilités.
M = np.array([x,y,z])
print(M)
print(my_array)
Sauvegarder des arrays¶
import numpy as np
x = np.arange(0.0,5.0,1.0)
np.savetxt('test.npy', x, delimiter=',')
Il existe également les 3 façons supplémentaires de sauvgarder un array dans un fichier texte:
save()sauvegarde un array au format binaire npysavez()sauvegarde plusieurs arrays au format non compressé npzsavez_compressed()sauvegarde plusieurs arrays et les compresse dans un npz
Vectorisation de fonctions¶
- toutes les fonctions ne fonctionnent pas automatiquement avec les arrays
- les fonctions qui fonctionnes avec les arrays sont dites vectorisées
- la majorité des fonctions de
numpysont vectorisées - on peut définir des fonctions vectorisées nous même (un peu comme la surcharge en C++) grâce a la fonction supérieure
numpy.vectorize()
def myfunc(x):
if x >= 0.5:
return x
else:
return 0.0
fv = np.vectorize(myfunc)
x = np.arange(0, 1, 0.1)
print(x)
print(fv(x))
Plot de base¶
dans jupyter plt.show() crash (se renseigner)
import matplotlib.pyplot as plt
# uniquement nécéssaire pour Jupyter:
%matplotlib inline
x = np.arange(0, 1, 0.1)
y = x*2 + 5
plt.plot(x, y)
- en éditeur on rajoute le .show() pour display
plot d'une sin¶
from numpy import pi, sin
x = np.arange(0, 2*pi, 0.01)
y = sin(x)
plt.plot(x, y)
plot de données¶
tps, Uch0, Uch1, Ut, It, pT = np.loadtxt('C:/Users/sol.rosca/Jupyter_notbooks/10khz.txt',
skiprows=0,
unpack=True)
x = tps
y = Uch0 -Uch1
plt.plot(x,y)

Matrices¶
import numpy as np
x = np.array([[1, 2], [3, 4]])
x
- nous pouvons transformer un array multidimensionnel en matrice
- une matrice est un objet qui permet des opérations différentes que celles qu'on fait sur les arrays
M = np.matrix(x)
M
Créer une matrice à partir de strings¶
- nous pouvons aussi créér des matrices directement à partir de strigs ce qui économise des touches:
- le point virgule (;) marque le début d'une nouvelle ligne
M = np.matrix('2 0; 0 2')
M
Plot multidimensionnel avec des matrices¶
- si nous utilisons
plot()pour ploter une matrice, ce dernier utilisera les valeurs de l'axe des y (colones de la matrice).
from numpy import pi, sin, cos
x = np.arange(0, 2*pi, 0.01)
y = sin(x)
ax = plt.plot(x, np.matrix([sin(x), cos(x)]).T)
Indexes et slices¶
Ces opérations sont très similaires aux opérations qu'on peut faire sur les listes.
Indexes¶
m = np.random.random((3,3,3))
print(m)
- retourne l'élément à l'indice 1
print(m[1])
- retourne l'élément de la première ligne, seconde colone $(1,2)$
print(m[1][2])
- même chose syntaxedifférente
print(m[1,2])
- retourne l'élément de le première ligne, première colone, et 2 èlement de l'axe des $\Large z$ $(1,1,2)$
print(m[1,1,2])
Slices¶
- basique:
n = np.array([[1,2], [3,4]])
print(n)
- accès aux colones:
o = n[:,1]
print(o)
- accès aux lignes:
p = n[:1]
print(p)
- même syntaxe pour les matrices:
N = np.matrix('6 7; 8 9')
print(N)
O = N[:,1]
print(O)
P = N[:1]
print(P)
- Les slices sont une référence à l'objet initial et non pas une copie
o[1] = 10
print(n)
O[1] = 10
print(N)
Copier des matrices et des vecteurs¶
- pour copier une matrice ou une slace de ses éléments, on utilise la fonction
np.copy()
M = np.matrix('1 2; 3 4')
a = np.copy(M[:,1])
print(a)
M[0,1] = -2
print(a)
Somme¶
- une façon de sommer les éléments d'un array ou d'une matrice est d'utiliser une boucle for
a = np.arange(0.0, 100.0, 10.0)
print(a)
result = 0.0
for x in a:
result += x
print(result)
Cette façon de faire est très couteuse en ressources. À éviter !
Somme efficace¶
- à la place de la boucle
fornous pouvons utiliser la fonctionsum() - cette fonction est écrite en C et est beaucoup plus performante
a = np.array([0, 1, 2, 3, 4])
print(np.sum(a))
Somme des lignes / colones¶
- quand nous avons affaire à des données multidimensionnelles, la fonction
sum()possède un argument axis qui ne permet de spécifier si nous désirons la somme des lignes ou des colonnes
M = np.matrix('1 2 3; 4 5 6; 7 8 9')
print(M)
- somme des lignes
print(np.sum(M, axis=0))
- somme des colonnes
print(np.sum(M, axis=1))
Arrays dans la pratique¶
import numpy as np
- les arrays sont des mutables et les variables qui les référencent peuvent pointer sur la même adresse
opérateur d'affectation (=)¶
- référence du même objet
x = np.array([1,2,3,4])
y = x
x is y
id(x), id(y)
x[0] = 9
y
x[0] = 1
z = x[:]
x is z
id(x), id(z)
x[0] = 8
z
methode copy()¶
- nouvel objet
x = np.array([1,2,3,4])
y = x.copy()
x is y
id(x), id(y)
x[0] = 9
x
y
opérations basiques¶
a = np.arange(4.0)
print(a)
b = a * 23.4
print(b)
c = b/(a+1)
print(c)
c += 10
print(c)
liste comme indexe¶
arr = np.arange(100,200)
print(arr)
select = [5,25,50,75,-5]
print(arr[select])
array de booléens¶
arr = np.arange(10, 20)
print(arr)
div_by_3 = (arr % 3 == 0)
print(div_by_3)
- on peut également utiliser une liste de booléens comme indice
print(arr[div_by_3])
Methodes sur les arrays¶
arr = np.arange(10, 20)
print(arr)
arr.reshape((2,5))
print(arr)
arr.sum()
arr.mean()
arr.std()
arr.max()
arr.min()
div_by_3.all()
div_by_3.any()
div_by_3.sum()
div_by_3.nonzero()
.nonzero()¶
A common use for nonzero is to find the indices of an array, where a condition is True. Given an array a, the condition a > 3 is a boolean array and since False is interpreted as 0, np.nonzero(a > 3) yields the indices of the a where the condition is true.
a = np.array([[1,2,3],[4,5,6],[7,8,9]])
a > 3
np.nonzero(a > 3)
- The nonzero method of the boolean array can also be called.
(a > 3).nonzero()
Tri d'arrays¶
- sort() agit directement sur l'array
Create the array a=[2.3 1.2 5.4 1.7 7 0.4 5.1 6.3] and sort the elements
a = np.array([2.3, 1.2, 5.4, 1.7, 7, 0.4, 5.1, 6.3])
b = np.sort(a)
print(b)
Sort the arguments and show the array b = [5 7 2 3 4 1 9 8] in the same order of the arguments.
c = np.array([5, 7, 2, 3, 4, 1, 9, 8])
s = a.argsort()
print(c[s])
Transposition d'arrays¶
What transposing your arrays actually does is permuting the dimensions of it. Or, in other words, you switch around the shape of the array. Let’s take a small example to show you the effect of transposition:
arr = np.array([[1,2,3,4],[5,6,7,8]])
print(arr)
print(np.transpose(arr))
- de façon équivalente on peut utiliser
.Tpour transposer:
print(arr.T)
Opérations sur les matrices¶
- Une fois que nous avons une matrice nous pouvons lui appliquer des opérations spécifiques à ces dernières
- pour transposer et inverser on utilise respectivement les attributs T et I
x = np.array([[1, 2], [3, 4]])
M = np.matrix(x)
M
transposition $M^T$:
M.T
inversion $M^{-1}$:
M.I
dot product:
j = np.array([[0.0, -1.0], [1.0, 0.0]])
print(j)
np.dot(j, j)
j = np.matrix('0. -1,; 1. 0.')
print(j)
np.dot(j, j)
Statistiques¶
- en plus des fonctions
mean()var()etstd()il existe aussi:
* median()
a = np.array([1, 4, 3, 8, 9, 2, 3])
np.median(a)
- corrcoef() coéfficient de corrélation
a = np.array([[1, 2, 1, 3], [5, 3, 1, 8]])
np.corrcoef(a)
- cov() covarince
np.cov(a)
Opération spécifiques aux matrices¶
a = np.array([[1,2],[3,4]])
M = np.matrix(a)
- résultat 1d:
a[0]
- résultat 2d:
M[0]
- $\large a \cdot a$ (élément x élément)
a * a
- multiplication algebrique de matrices
M * M
- element-wise power
a**3
- multiplication de matrices $\large M \cdot M \cdot M$
M**3
- transposition $M^T$:
M.T
- transposition conjuguée (!= de .T pour des matrices complexes)
M.H
- inversion $M^{-1}$:
M.I
Opérations entre arrays¶
a = np.array([1,2,3])
b = np.array([5,2,6])
a + b
a - b
a * b
b / a
a % b
b**a
a = np.array([[1, 2], [3, 4], [5, 6]], float)
b = np.array([-1, 3], float)
a
b
a + b
a * a
b * b
a * b
List comprehension¶
A = np.array([[n+m*10 for n in range(5)] for m in range(5)])
A
v = np.arange(0,5)
v
np.dot(A,A)
np.dot(A,v)
np.dot(v,v)
Cast¶
- nous pouvons cast un array en matrice ce qui a donc pour effet de changer le comportement des opérateurs $+,-,\cdot$
M = np.matrix(A)
v2 = np.matrix(v).T
v2
M*v2
- produit interne
v2.T * v2
- algèbre linéaire standard
v2 + M*v2
Exercices
EXERCICES¶
Numpy Vectors and Matrices¶
import numpy as np
a = np.array([1,3,5,7,9])
b = np.array([3,5,6,7,9])
c = np.linspace(0, 1, 100)
A = np.array([[1, 2, 3], [3, 6, 7], [2, 5, 6]] )
B = np.zeros((5,6))
C = np.ones((4,6))
D = np.random.rand(3,4)
1. Print the shape, size and the type.¶
l = [a,b,c,A,B,C,D]
for i in l:
print("\nshape: {}\nsize: {}\ndtype: {}\ntype: {}\narray:\n{}\n\n"
.format(i.shape, i.size, i.dtype, type(i), i))
2. Transpose and invert the matrix A. What happens if in A you replace 7 by 9? Why?¶
print(A)
print((np.matrix(A).T).I)
A[1,2] = 9
print(A)
That happens and I don't know why
print((np.matrix(A).T).I)
3.¶
a. Make a dot product between A and D.¶
print(np.dot(A, D))
b. Make a dot product between D and A.¶
print(np.dot(D, A))
c. Make a dot product between the transpose of D and A.¶
print(np.dot(D.T, A))
d. Make a dot product between D and C.¶
print(np.dot(D, C))
Save and Load¶
a. Create a 1000 x 2000 random matrix with numbers from 0 to 1 and save it to a file called data.npy¶
m = np.random.random((1000, 2000))
print(m)
np.save('C:/Users/sol.rosca/Jupyter_notbooks/data.npy',m)
b. Load the matrix from the file and compare it to the original file.¶
# n = np.empty((1000,2000))
n = np.load('C:/Users/sol.rosca/Jupyter_notbooks/data.npy')
print(n)
print((n==m).all())
Reshape¶
a. Create an array of all numbers from 101 to 270 and reshape it into a matrix of 17 rows and 10 columns.¶
a = np.arange(101,271)
print(a)
a = a.reshape(17,10)
print(a)
b. Calculate the sum, the mean, the max and the min element in the 9th row.¶
print(a[8])
print(np.sum(a[8]))
print(np.mean(a[8]))
print(np.max(a[8]))
print(np.min(a[8]))
c. Print all the elements that are divisible by 11.¶
print(a[np.where(a % 11 == 0)])
# equivalents
print(a[np.nonzero(a % 11 == 0)])
for i in a[np.nonzero(a % 11 == 0)]: print(i, end=' ')
d. print their sum.¶
print(np.sum(a[np.nonzero(a % 11 == 0)]))
Sort¶
a. Create the array a=[2.3 1.2 5.4 1.7 7 0.4 5.1 6.3] and sort the elements¶
a = np.array([2.3, 1.2, 5.4, 1.7, 7, 0.4, 5.1, 6.3])
b = np.sort(a)
print(b)
b. Sort the arguments and show the array b = [5 7 2 3 4 1 9 8] in the same order of the arguments.¶
c = np.array([5, 7, 2, 3, 4, 1, 9, 8])
s = a.argsort()
print(c[s])
Matrices¶
a. Create the matrix M=[2,3;4 1] using mat() calculate:¶
- $ M \cdot M $
M = np.mat('2 3; 4 1')
print(M*M)
- $ M^5 $
print(M**5)
- $ M^T $
print(M.T)
- $ M^{-1} $
print(M.I)
b. What happens if instead of mat() you use array?¶
You can't invert an array $ (a^{-1})$
- $ a \cdot a $
a = np.array([[2,3], [4,1]])
print(a*a)
- $ a^5 $
print(a**5)
- $ a^T $
print(a.T)
Matplot¶
Figures¶
Plot in green the function y = x ** 4 for x between -2 and 2 using 100 points. Label the figure properly.
import numpy as np
import matplotlib.pyplot as plt
from pylab import *
%matplotlib inline
x = np.linspace(-2, 2, 100)
y = x**4
fig, ax = plt.subplots(figsize=(12,6), dpi=180)
matplotlib.rcParams.update({'font.size': 8, 'font.family': 'serif'})
ax.grid(True)
ax.plot(x, x**4, 'g', label=r"$ y = x^4 $", linewidth=2)
ax.legend(loc=2, fontsize=14); # upper left corner
ax.set_xlabel(r'$x$', fontsize=18)
ax.set_ylabel(r'$y$', fontsize=18)
ax.set_title('$y = f(x^4)$', fontsize=18);

Subplots¶
Plot in the same figure two subplots one above each other:
- The absolute value
- The angle Of the following function:
Y = 1/(1+j*w)
If w takes values between -10 and 10 in 500 steps.
- Label the plots.
x = np.arange(-10, 10, 20/500)
y = 1/(1+x)
fig, axes = plt.subplots(2, 1, figsize=(12,6), dpi=180)
matplotlib.rcParams.update({'font.size': 8, 'font.family': 'serif'})
axes[0].plot(y, abs(x), 'r', label="lab 1")
axes[1].plot(x,y, 'b', label="lab 2")
axes[0].set_title('title');
axes[1].set_title('title');
axes[0].legend(loc=2); # upper left corner
axes[1].legend(loc=3); # upper left corner

Multiple plots¶
Plot the functions sin(t) and cos(t) at the same plot and put a legend.
fig, axes = plt.subplots(figsize=(12,6), dpi=180)
matplotlib.rcParams.update({'font.size': 12, 'font.family': 'serif'})
t = np.linspace(-np.pi, np.pi, 256, endpoint=True)
C,S = np.cos(t), np.sin(t)
plt.xlim(t.min()*1.1, t.max()*1.1)
plt.ylim(C.min()*1.1, C.max()*1.1)
ax = plt.gca()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.xaxis.set_ticks_position('bottom')
ax.spines['bottom'].set_position(('data',0))
ax.yaxis.set_ticks_position('left')
ax.spines['left'].set_position(('data',0))
plt.xticks([-np.pi, -np.pi/2, 0, np.pi/2, np.pi],
[r'$-\pi$', r'$-\pi/2$', r'$0$', r'$+\pi/2$', r'$+\pi$'])
plt.yticks([-1, 0, +1],
[r'$-1$', r'$0$', r'$+1$'])
plt.plot(t, C, color="blue", linewidth=2.5, linestyle="-", label="cosine")
plt.plot(t, S, color="red", linewidth=2.5, linestyle="-", label="sine")
plt.legend(loc='upper left', frameon=False)
plt.show()
